Handwritten Text Recognition (HTR) is a technology to convert handwritten text in images to machine-readable form.
- Commonly used for digitizing handwritten documents so that they can be electronically edited, searched, stored, or displayed on-line
- Allows preservation of heritage data that might not last much longer in their physical form, due to degradations with time
- Enables exploration of our cultural heritage
AttentionHTR: Handwritten Text Recognition Based on Attention Encoder-Decoder Networks
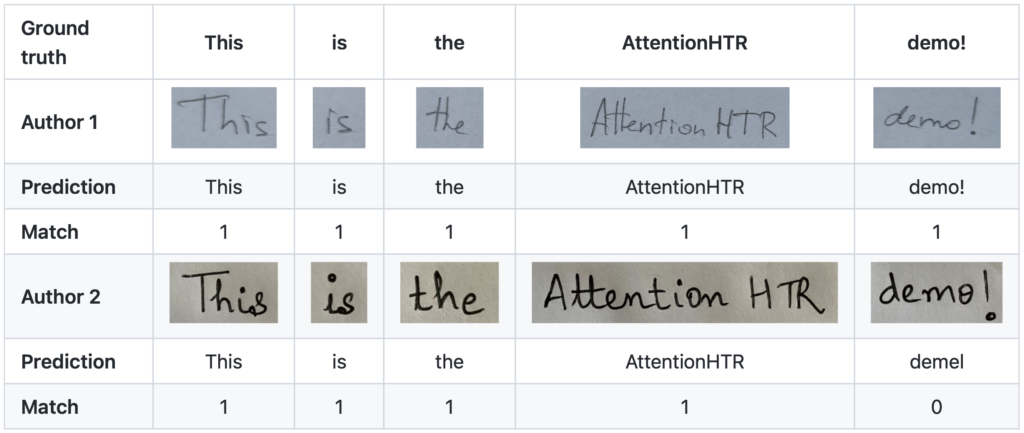
This work proposes an attention-based sequence-to-sequence model for handwritten word recognition and explores transfer learning for data-efficient training of HTR systems. To overcome training data scarcity, this work leverages models pre-trained on scene text images as a starting point towards tailoring the handwriting recognition models. ResNet feature extraction and bidirectional LSTM-based sequence modeling stages together form an encoder. The prediction stage consists of a decoder and a content-based attention mechanism. The effectiveness of the proposed end-to-end HTR system has been empirically evaluated on a novel multi-writer dataset Imgur5K and the IAM dataset. The experimental results evaluate the performance of the HTR framework, further supported by an in-depth analysis of the error cases.
AttentionHTR is simple, modular, and reproducible, more data can be easily added in the pipeline, further strengthening the model’s accuracy. Source code, demo and pre-trained models are available at GitHub.
Dmitrijs Kass and Ekta Vats, AttentionHTR: Handwritten Text Recognition Based on Attention Encoder-Decoder Networks, In: Uchida, S., Barney, E., Eglin, V. (eds) Document Analysis Systems. DAS 2022. Lecture Notes in Computer Science, pp 507–522, vol 13237. Springer, Cham. Paper

Uncovering the Handwritten Text in the Margins
This work presents an end-to-end framework for automatic detection and recognition of handwritten marginalia, and leverages data augmentation and transfer learning to overcome training data scarcity. The detection phase involves investigation of R-CNN and Faster R-CNN networks. The recognition phase includes an attention-based sequence-to-sequence model, with ResNet feature extraction, bidirectional LSTM-based sequence modeling, and attention-based prediction of marginalia. The effectiveness of the proposed framework has been empirically evaluated on the data from early book collections found in the Uppsala University Library in Sweden.
Liang Cheng, Jonas Frankemölle, Adam Axelsson and Ekta Vats, Uncovering the Handwritten Text in the Margins: End-to-end Handwritten Text Detection and Recognition. In the Proceedings of the 8th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, co-located with the 18th Conference of the European Chapter of the Association for Computational Linguistic (EACL 2024). Paper


Image source: Uppsala University Library, Alvin portal.
Why marginalia is important?
- Preservation and access: The Marginalia, notes, and annotations found in historical documents, manuscripts, and books provide valuable insights into the thoughts, reactions, and interpretations of past readers.
- Textual scholarship: Marginalia often include corrections, annotations, and commentary that shed light on variant readings, textual discrepancies, and the transmission history of texts.
- Understanding reader reception: By analyzing the content, language, and placement of marginalia, researchers can better understand how texts were received, interpreted, and appropriated by readers over time. This can provide valuable insights into changing literary tastes, cultural norms, and intellectual movements.
- Interdisciplinary research: Marginalia can contribute towards Interdisciplinary Research in the area where Marginalia data can be of interest to scholars working in diverse fields such as literary studies, history, sociology, linguistics, and cognitive science.
Leveraging Generative AI Models for Handwritten Text Image Synthesis
In recent times, deep learning based methods have achieved significant performance in handwritten text recognition. However, handwriting recognition using deep learning needs training data, and often, text must be previously segmented into lines (or even words). These limitations constrain the application of HTR techniques in document collections, because training data or segmented words are not always available. This project aims at addressing this issue by leveraging diffusion models to facilitate HTR tasks by generating realistic synthetic images that resemble a real distribution and enhance the training of downstream HTR tasks.
Team: Alex Kangas, Liam Tabibzadeh and Vasileios Toumpanakis (Data Science Project, 2023)

Document Binarisation
Document image binarization aims to separate the foreground text in a document from the noisy background during the preprocessing stage of document analysis. Document images commonly suffer from various degradations over time, rendering document image binarization a daunting task. Typically, a document image can be heavily degraded due to ink bleed-through, faded ink, wrinkles, stains, missing data, contrast variation, warping effect, and noise due to lighting variation during document scanning. Though document image binarization has been extensively studied, their performance for heavily degraded ancient manuscripts is significantly low. This project aims at developing document binarization methods, especially tailored for heavily degraded Swedish texts. Two approaches towards binarisation are investigated: U-Net based and improved DeepOtsu, with a real-world use case of using ancient manuscripts from the 17th-18th century from the National archive in Sweden.
Team: Simon Leijon, Hampus Widén, Martin Sundberg, Petter Sigfridsson and Jonathan Kurén (Data Science Project, 2021)

- Prashant Singh, Ekta Vats and Anders Hast, Learning Surrogate Models of Document Image Quality Metrics for Automated Document Image Processing, In Proceedings of the 13th IAPR International Workshop on Document Analysis Systems (DAS), Pages 67-72, 2018. Paper
- Ekta Vats, Anders Hast and Prashant Singh, Automatic Document Image Binarization using Bayesian Optimization, In Proceedings of the 4th International Workshop on Historical Document Imaging and Processing (HIP 2017), Kyoto, Japan, ACM Press, Pages 89–94, 2017. Paper